Colbert vs rerankers
How to re-rank your snippets in RAG ⇒ ColBERT vs Rerankers vs Cross-Encoders ⚔️
Let’s say you’re doing RAG, and in an effort to improve performance, you try to rerank a few possible source snippets by their relevancy to a query.
How can you score similarity between your query and any source document? 🤔 📄 ↔️ 📑
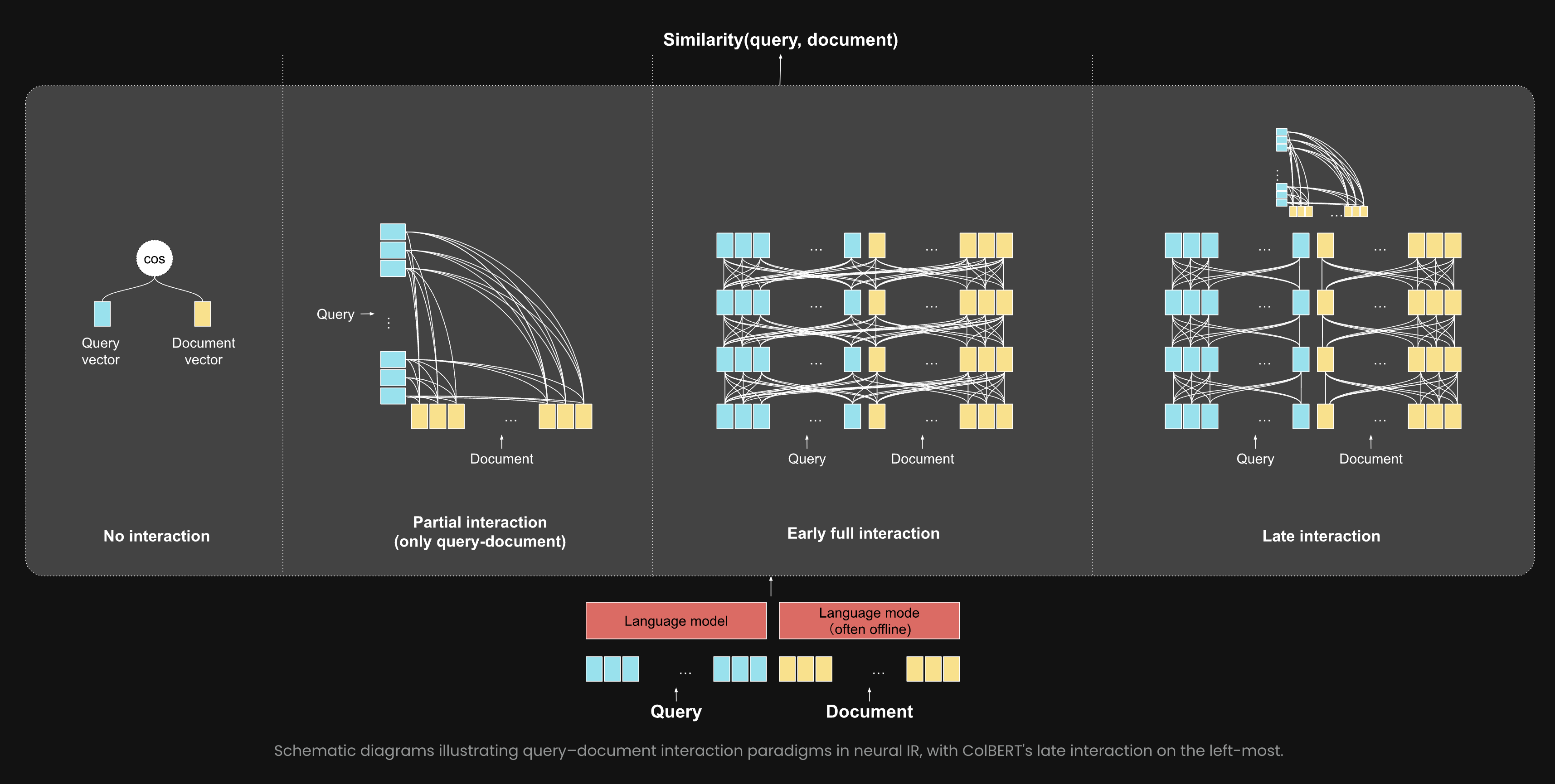
- Just use embeddings : No-interaction 🏎️
This means that you encode each token from both the query and the doc as separate vectors, then average the tokens of each separately to get in total 2 vectors, then you compute similarity via cosine or something.
➡️ Notable examples: Check the top of the MTEB leaderboard!
- Late-interaction: this is ColBERT 🏃
These encode each token from both query and doc as separate vectors as before, but compare all together without previously averaging them and losing information.
This is more accurate than no-interaction but also slower because you have to compare n*m vectors instead of 2. At least you can store documents in memory. And ColBERT has some optimisations like pooling to be faster.
➡️ Notable examples: ColBERTv2, mxbai-colbert-large-v1, jina-colbert-v2
- Early interaction: Cross-encoders 🏋️
Basically you run the concatenated query + document in a model to get a final score.
This is the most accurate, but also the slowest since it gets really long when you have many docs to rerank! And you cannot pre-store embeddings.
➡️ Notable examples: MixedBread or Jina AI rerankers!
🚀 So what you choose is a trade-off between speed and accuracy: I think ColBERT is often a really good choice!
Accuracy of ColBERT vs Cross-encoders: this is approximate, but for Jina AI models, on NDCG@10 for BEIR datasets, on average rerankers (=cross-encoders) score about 70% vs 50% for ColBERT models.
Based on this great post by Jina AI 👉 https://jina.ai/news/what-is-colbert-and-late-interaction-and-why-they-matter-in-search/