o1 human preference is grokked
Great insight from o1 blog: Human vibe tests for LLM strength are now grokked ✅
Ever heard of “grokking”? It is the moment when suddenly during training, a LLM’s performance on any benchmark jump from “random answers” to “close to 100%”.
This term, although first meant to be funny, is quite relevant in the LLM space, because it illustrates how benchmarks being solved are a discrete projection of the models’s performance : a model’s underlying strength may grow in a boring, linear fashion, but its projection on your benchmark is a really steep sigmoid curve, nearly discrete.
👉 You’re a researcher, you’ve just build a nice, hard benchmark. Way too hard for currrent models to beat. You see the front runner culminating at <10% performance, you’re like “ok I’ve got 1 year before my benchmark is beaten”.
The front runner is making progress, but it’s like a tiny spot on the road below: so although it seems to be racing fast, from where you stand it’s still like not moving at all.
And then it starts growing a bit quicker, and wow wait actually it’s freaking fast, and - woosh- it’s just passed in front of you in the roar of its thrusters, and now it’s a tiny spot again, but on the other side, and you couldn’t tell how far it is now.
It has just gone from 0 to 100%.
And now your benchmark is grokked.
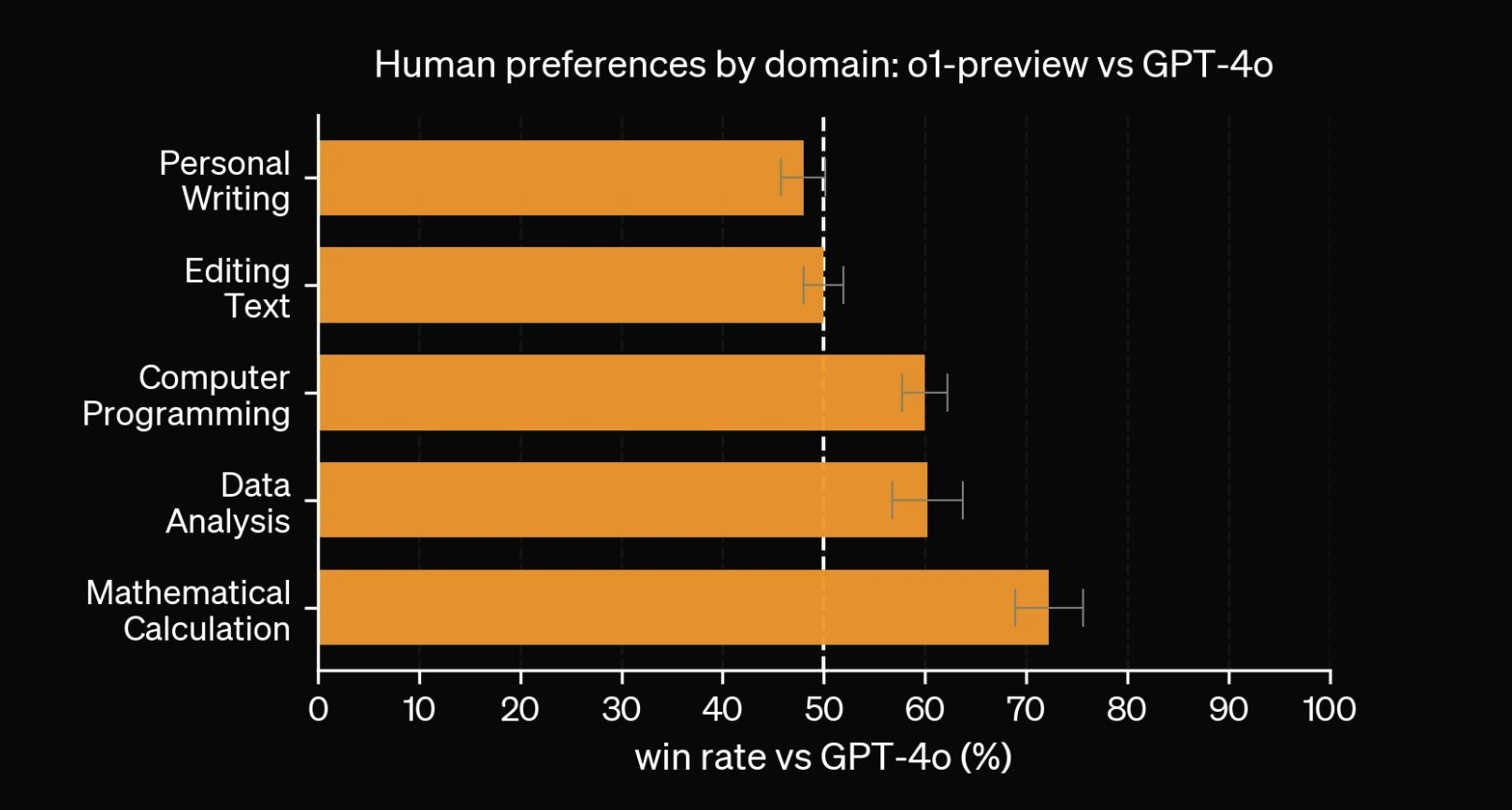
Now it seems human preference is about to be grokked too.
I’ve shared earlier about how LLM builders could change their models to game human preference, for instance by making the answers more assertive (I heard corporate manager types have also learnt to do this). Fine-tuning on LMSys data like Gemma 2 models do is doing just this.
The o1 report, on top of mentioning that MATH and GSM8K benchmarks are now grokked so no more relevant, show that for “Personal writing” or “Editing text”, GPT-4o is actually equal or preferred by human to o1-preview, while o1 is clearly “smarter” on more advanced tasks : I interpret this as meaning, not that o1 is not good, but that our basic vibe tests don’t work anymore. We’re reaching the steepest part of the sigmoid, soon we may not be able to check the real performance of LLMs with just prompts, and we’ll need carefully-crafted benchmarks instead.