Brève histoire de l’intelligence artificielle
L’intelligence artificielle (on notera souvent ce terme par l’abréviation “IA”) vit aujourd’hui un bouillonnement d’idées et de développements sans aucun précédent dans toute l’histoire de la science. Mais son développement ne date pas d’hier ; pour reprendre à ses débuts, il nous faut retourner au milieu du siècle passé. En étudiant l’histoire de l’IA, une saga pleine de coups de tonnerre et de revirements, nous verrons se mettre en place les principales briques techniques des modèles que nous utilisons aujourd’hui.
Symbolistes contre connexionistes
A partir des années 1950, avec l’apparition des premiers ordinateurs, et la capacité de leur faire exécuter des algorithmes1, on s’aperçoit que les machines peuvent désormais résoudre certaines tâches mentales élémentaires : calcul mental, tri de listes, résolution d’équations simples… Une question jaillit aussitôt : “Pourra-t-on rendre ces machines plus intelligentes, peut-être à l’égal de l’Homme ?” C’est le début d’une quête passionnante.
⚙️ Brique technique: les Algorithmes
Qu’est ce qu’un algorithme? C’est une suite ordonnée d’étapes pré-définies, dont l’exécution permet de résoudre une tâche. Une recette de cuisine est un algorithme. On les exprime souvent en pseudocode. Voilà un exemple de pseudocode pour un algorithme :
Entrée : liste l
somme = 0
Pour chaque élément de la liste, noté m :
somme devient somme + m
somme devient somme / longueur(l)
Renvoyer somme
Cet algorithme calcule la moyenne d’une liste de nombres. La ordinateurs actuels ne brillent pas par leur esprit d’initiative (ils n’en ont rigoureusement aucune tant qu’on ne leur a pas donné d’instructions), mais ils sont capables d’appliquer des règles simples avec une rapidité immense : ils sont donc extrêmement puissants pour l’exécution d’algorithmes.
Mais comment construire une machine qui pense? Une première approche, imaginée par Frank Rosenblatt dès 1950, veut reconstruire le raisonnement par le bas, en partant de briques de raisonnement simplissimes. Il prend l’exemple d’une fourmilière : une fourmi prend ses décisions par des raisonnement simples, presque mécaniques. Mais en faisant fonctionner et interagir un grand nombre de ces mécanismes simple, la fourmilière dans son ensemble parvient à obtenir des comportements complexes qui lui permettant d’explorer et utiliser efficacement son environnement. Pourquoi ne pas combiner mécanismes élémentaires pour remonter à des niveaux d’abstraction plus élevés, jusqu’à parvenir à résoudre des tâches complexes? Rosenblatt crée des fonctions mathématiques élémentaires qu’il appelle des neurons : ces neurons prennent en entrée plusieurs signaux, les combinent et les transforment pour obtenir un seul canal de sortie. Si en sommant tous ces signaux, la somme est supérieur à un certain seuil, le neuron s’active, et donne en sortie la somme en question, sinon, il donne 02. On peut former une connexion de la sortie d’un neuron à l’entrée d’un autre, et former ainsi des couches successives, en assignant un poids particulier à chaque connexion. Par exemple, construisons un réseau de neurones pour détecter quel est l’animal présent sur une image. Le neuron a situé sur la couche 1 détectera la proposition A, par exemple “couleur orange”, et le neuron b situé sur la couche 2 détectera la proposition B, “l’image représente un renard”. Dans ce cas, on veut que la connexion du neuron a vers le neuron b soit positive: ainsi quand on a détecté une couleur orange, comme il est probable qu’un animal orange soit un renard, il y aura un signal positif pour aider B à s’activer aussi. A l’inverse, si le neuron c situé lui aussi sur la couche 2 détecte la condition C, “l’image représente un éléphant”, on préfère que la connexion de a vers c soit négative: si l’image est orange, ce n’est probablement pas un éléphant. Chaque couche successive peut ainsi s’appuyer sur les précédentes pour monter d’un niveau d’abstraction: si la couche 0 est le signal direct des pixels, couche 1 représente des couleurs et formes élémentaires, la couche 2 peut déjà représenter des motifs et formes plus avancées, la 3 peut représenter des concepts comme “griffe” ou “oreille”, et la 4 peut déterminer de quel animal il s’agit. Cette approche est la première ébauche des grands modèles d’aujourd’hui.
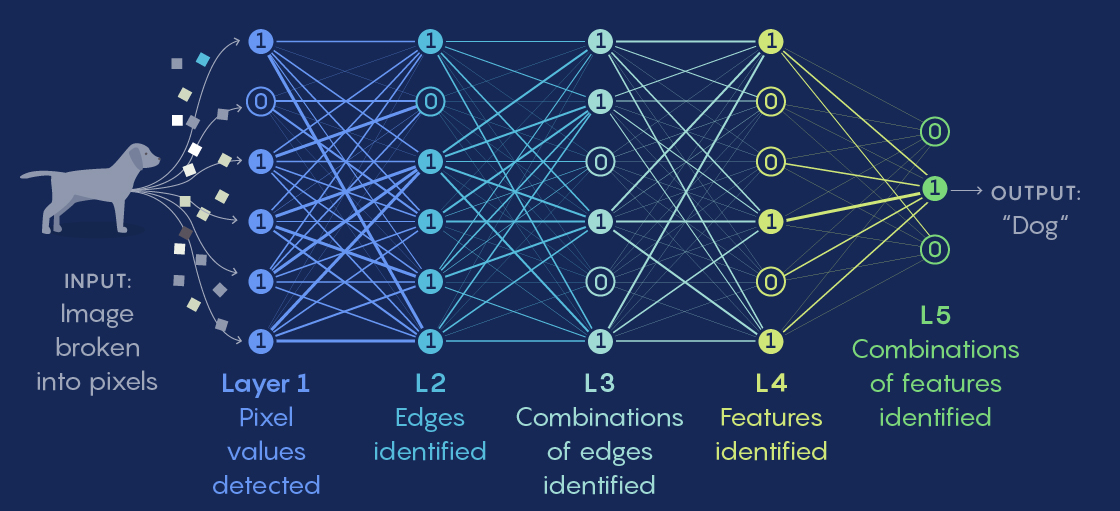
Des approximateurs universels
Si l’on connectait juste entre eux des neurons qui somment des signaux avec certains coefficients, on obtiendrait un système linéaire : c’est à dire qu’en multipliant tous les signaux d’entrée (par exemple la valeur des pixels) par un même coefficient, la sortie serait aussi multipliée par ce coefficient. Un tel réseau ne serait pas très utile: dans notre exemple de la classification d’image, si on divise par deux la luminosité de l’image, donc la valeur de chaque pixel, la valeur du neurone en sortie serait aussi divisée par deux, donc la classification “ceci est un chat” deviendrait deux fois moins certaine, ce qui serait absurde : la nuit, les chats sont peut-être gris mais ils restent des chats. La clé de l’efficacité des réseaux de neurones réside dans la fonction non linéaire qui est appliquée à la somme en sortie du neurone: c’est elle qui donne au réseau de neurones son caractère non linéaire. En fait, un réseau de neurones est un approximateur universel : il peut reproduire aussi finement qu’on le veut n’importe quelle fonction de ses entrées, pourvu qu’on lui laisse assez de couches intermédiaires et que ses poids soient ajustés correctement.
L’hiver de l’intelligence artificielle
L’approche de Rosenblatt, appelée “connexioniste” car elle repose sur la connexion de nombreux éléments simples, connaît des premiers succès et une publicité tapageuse3, mais fait vite face à des critiques. En effet, ce modèle de réseau peut fonctionner, mais comment déterminer les poids des connexions? S’il faut régler manuellement chacun des poids de chaque connexion afin d’avoir un bon résultat sur notre problème, il sera extrêmement couteux d’adapter le réseau à chaque nouveau problème ou chaque nouveau point de données. C’est là un problème crucial: l’apprentissage. C’est cette limitation qui fait tomber en disgrâce l’approche connexioniste. Pendant des années, une autre approche prend le dessus : l’approche symbolique. L’approche symbolique consiste à créer des raisonnement par l’autre côté : en partant d’un haut niveau d’abstraction. Cette école cherche donc à représenter l’ensemble des raisonnements possibles dans un langage symbolique. Une fois la situation exprimée sous forme d’une phrase dans ce langage symbolique, il deviendrait simple, en utilisant des règles de calcul prédéterminées, de transformer la phrase en une conclusion logique. Cette approche est séduisante sur un plan théorique car plus explicable. Mais elle est extrêmement ambitieuse: est il possible d’exprimer toutes les décisions que nous prenons, mêmes celles qui sont faites machinalement4, en un langage théorique? Car ce langage devrait pouvoir exprimer avec exactitude l’intégralité des concepts du monde, et même les imaginaires. Ensuite, une telle IA aurait des processus de raisonnement discrets: les entrées ne pourraient être que des symboles présents ou pas, donc des 0 ou des 1. Mais est-ce que beaucoup de nos raisonnements ne sont pas une somme floue de paramètres continus? Par exemple, quand je décide de sortir ou non, je prends en compte la météo: mais la couleur du ciel varie sur un spectre continu sur toutes les nuances du gris au bleu, et supprimer cette nuance fait certainement perdre de la qualité au raisonnement. Pour pallier la difficulté induite par cette complexité, la communauté symboliste commence alors par développer des systèmes experts restreints à un domaine spécifique. Mais ils sont très coûteux à concevoir pour une faible performance : cette approche porte peu de fruit. Et c’est ainsi que commence ce qu’on a appelé “hiver de l’IA”, une longue période de stagnation et de doute.
Yann LeCun et la Rétropropagation (Backpropagation)
En science, les révolutions commencent souvent à la marge. Dans les années 90, le jeune Yann LeCun commence à s’y intéresser à l’intelligence artificielle. Il lit le compte rendu d’un débat où le linguiste Noam Chomsky affirmait que le cerveau avait des structures pré-établies pour apprendre à parler. Face à lui, le psychologue du développement Jean Piaget défendait l’idée que tout s’apprend, même une partie des structures du langage, et que la construction du langage se fait progressivement au fil du développement de l’intelligence5. Qui a raison: le raisonnement se fait il à partir de structure pré-construites ou peut-il émerger de mécanismes simples? Cette question va être structurante dans le développement de l’intelligence artificielle. Yann LeCun va dès lors faire de l’apprentissage sa ligne directrice. Il reprend les réseaux de neurons de Rosenblatt, et reprend une technique de rétropropagation de gradient qui existait depuis les années 60 en théorie du contrôle6 mais que Rosenblatt semblait ignorer, récemment re-théorisée par Rumelhart et le canadien Hinton, qui permet théoriquement d’entraîner un réseau de neurons à plusieurs couches, c’est à dire de l’adapter à un jeu de données. LeCun consolide la théorie7 et obtient pour la première fois un modèle capable d’apprendre à partir d’un jeu de données. Il l’applique à la reconnaissance de chiffres sur des photos de chiffres manuscrits, compressées en 28x28 pixels8. La démonstration est impressionnante, bien meilleure que tous les systèmes existants à l’époque. A la fin des années 90, son système traite 10 à 20% de tous les chèques aux Etats-Unis.
Problèmes de prédiction : classification et régression
Il existe plusieurs formulations de problèmes que l’on peut vouloir donner à résoudre aux intelligences artificielles. On veut toujours prédire une sortie en fonction d’une entrée - chacune de ces dernières pouvant comporter un ou plusieurs éléments. Si la sortie est discrète, c’est à dire qu’elle doit appartenir à un nombre fini de catégories, on appellera cela un problème de classification. Par exemple, si on demande “Quel type d’animal est-ce là ?» en donnant en entrée une photo d’animal (qui est un ensemble de pixels uniques), c’est un problème de classification. La régression est la configuration où la sortie peut prendre des valeurs continues tout au long d’un axe : par exemple “toutes les valeur entre 0 et 1”. La question “Combien vaut l’action NVIDIA au temps t ?” est une question de régression. Dans l’exemple de l’outil développé par Yann LeCun ci-dessus, l’objectif est de prédire un chiffre entre 0 et 9 : il s’agit donc d’un problème de classification.
Apprentissage, puis Inférence
Yann LeCun a été parmi les pionniers de l’apprentissage. Aujourd’hui, les deux étapes fondamentales de l’intelligence artificielle sont : apprentissage et inférence. Il est important de toujours garder en tête cette distinction. L’apprentissage est l’étape où l’on adapte les poids du modèle pour lui donner une capacité à raisonner, l’inférence est celle où il le modèle prédit un résultat en fonction de ses entrées. Quand on parle d’entraînement ou d’optimisation, il s’agit de l’étape d’apprentissage. Quand on parle de prédiction ou de génération, c’est de l’inférence. Prenons l’exemple de ChatGPT. Il s’agit d’un produit (un chatbot) proposé par OpenAI, qui est propulsé par un de leurs modèles, par exemple GPT-4. L’entraînement est prodigieusement coûteux - des millions d’euros - et dure des mois. C’est pour cela que la “connaissance” du modèle (nous verrons plus loin que cette connaissance est extrêmement floue) s’arrête à une certaine date : les informations de la veille ne peuvent pas être encore intégrées, il faudrait au moins quelques semaines pour ré-entraîner le modèle avec ces informations. Au contraire, quand un utilisateur discute avec le chatbot, c’est seulement de l’inférence, beaucoup plus rapide (quelques millisecondes) et moins coûteuse (quelques millièmes de centimes). Le modèle n’apprend pas de ce qu’on lui raconte - il peut semble s’en souvenir car il génère son texte à partir de toute la conversation depuis le début, mais dès qu’on change de conversation, il repart à zéro. En revanche, la discussion pourrait très bien être sauvegardée comme matériau de construction pour les jeux de données d’entraînement des futurs modèles d’OpenAI.
⚙️ Brique technique: Entraînement par Rétropropagation
Comment changer les poids des connexions d’un réseau de neurones pour le rendre performant sur un problème? Par exemple, partant d’un réseau qui a des poids initialisés au hasard, comment l’entraîner à reconnaître l’animal qui figure sur une photo? On commence par ajouter au réseau une dernière couche de neurones, qui a autant de neurones que de classes de prédiction possibles. Par exemple, on peut entraîner le réseau à reconnaître seulement 1. Un chat, 2. Un chien. On ajoute donc une couche finale de 2 neurones: si le neurone n°1 s’active avec une valeur plus haute, la prédiction est “un chat”, si c’est le n°2, c’est un chien. Bien sûr à cet étape, comme les poids sont créés au hasard, les prédictions seront aléatoires. On veut donc entraîner le réseau, c’est à dire ajuster ses poids pour avoir des prédictions correctes. Pour cela, on a besoin d’un jeu de données contenant des photos d’animaux, annotées avec le nom de chaque animal. Par exemple: (photo_1193.jpg, “un chat”). Puis (photo_2194.jpg, “un chien”), etc. Nous devons donc trouver les paramètres (ici les poids des connexions) qui minimisent l’erreur (le nombre de prédictions fausses). Pour cela, on va modifier l’ensemble de nos paramètres par petits pas. A chaque pas, on va:
- Prendre un nouvel exemple de notre jeu de données, qui est un couple photo - nom d’animal.
- Calculer la prédiction pour l’image en question. Ensuite, on la compare au vrai nom d’animal: est- ce que la prédiction est fausse ou correcte?
- Si elle est correcte, on récompense les poids qui ont aidé à la prédire en les renforçant; si elle est fausse, on doit pénaliser les poids responsables en les amenuisant. Pour exécuter cet ajustement et répartir la responsabilité d’une erreur ou d’un succès entre tous les poids, on remonte depuis la fin du réseau: c’est là l’opération de rétro-propagation.
Cette opération est répétée des centaines de milliers de fois : c’est le processus d’optimisation, qui va converger progressivement vers une meilleure configuration des poids donnant une bonne performance prédictive au modèle.
Cet algorithme a connu quelques réglages depuis, mais c’est toujours le même qui sous-tend l’intégralité de l’intelligence artificielle aujourd’hui.
⚙️ Brique technique: Optimisation - trouver la vallée la plus basse.
Un peu trop de barbarismes ici, n’est ce pas? Ne vous inquiétez pas, après ce point technique, je vous laisse tranquilles pendant quelques pages! Et nous allons expliquer ci-dessous pourquoi les réseaux de neurones profonds sont plus durs à entraîner que d’autres algorithmes d’IA. Pour faire notre optimisation, vous avez vu juste au dessus qu’on faisait un petit pas par rétro-propagation. Mais essayons de mieux comprendre ce qui se passe. Reprenons le problème de l’entraînement d’un réseau de neurones. Que veut-on obtenir à la fin? On veut obtenir le meilleur jeu de paramètres dans le réseau, celui qui nous donne une erreur moyenne la plus petite possible sur notre jeu de données d’entraînement. On appelle cette erreur moyenne la “fonction de coût”9 : “coût” parce que l’erreur est un coût qu’on veut minimiser, et “fonction” car cette erreur moyenne varie en fonction des paramètres : quand on fait varier chaque paramètre, l’erreur moyenne varie en conséquence. Maintenant, comment trouver le meilleur jeu de paramètres pour minimiser cette fonction de coût? Pour simplifier la représentation du problème, prenons un réseau à deux paramètres, a et b. C’est bien sûr une simplification drastique de la réalité où les modèles ont des milliards de paramètres. Mais elle est pratique car nous pouvons représenter la fonction de coût sur un graphe en 3D : on note le paramètre A selon l’axe X, le paramètre B selon l’axe Y, et la fonction de coût du réseau (qui dépend donc des paramètres A et B) selon l’axe Z.
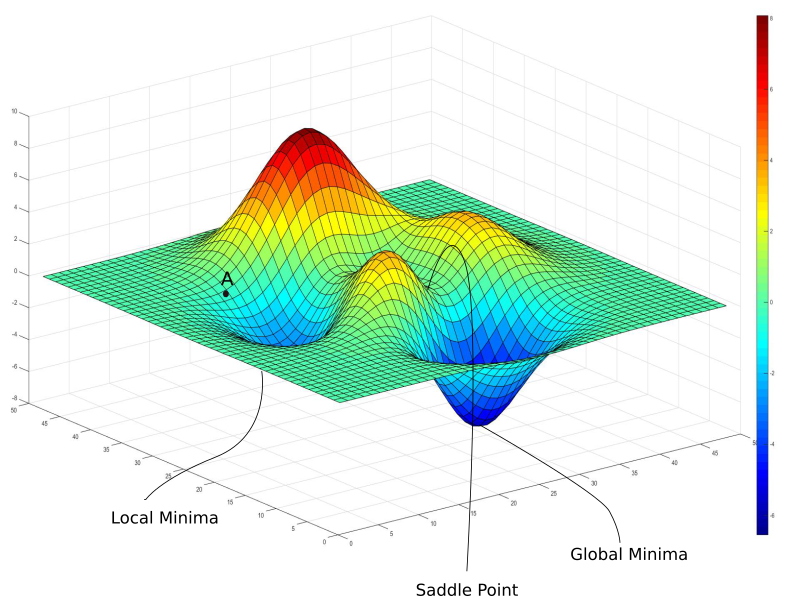
La fonction de coût varie en fonction de ses deux paramètres : on obtient un joli paysage. Attention, ce graphe n’a rien à voir avec le précédent : ici les axes X et Y représentent des paramètres, alors que dans le précédent, X et Y étaient des entrées du système. Le seul point commun de ces deux graphes est d’être en 3D. Que signifient les reliefs de ce paysage, montagnes et vallées, et quel endroit veut-on trouver ?
Les montagnes correspondent à des jeux de paramètres pour lequel le réseau est mauvais puisque son erreur moyenne est haute. A l’inverse, les vallées sont des minimum locaux, qui correspondent à des bons jeux de paramètres minimisant l’erreur. Notre but est donc de trouver la plus profonde de toutes les vallées, le minimum global. Comme nos paramètres A et B ont été initialisés au hasard, le placement initial dans le paysage est aléatoire. Tout le but de l’optimisation est de trouver la vallée la plus profonde en partant de ce point.
Pourquoi ne pas directement calculer le minimum global ? Eh bien, avec plaisir, mais comment faire? Le paysage qu’on a dessiné ici est simple, on pourrait le quadriller en une grille de 20 valeurs sur chaque axe, on aurait 400 combinaisons à tester, et ce serait plié. Oui mais souvenez vous qu’on a simplifié énormément le problème : en réalité, les réseaux ont souvent des millions de paramètres. Pour un million de paramètres, avec 20 valeurs sur chaque axe, il y aurait aurait 20*1,000,000 jeux de paramètres à tester, nous y serions encore dans des siècles. On se trouve donc dans la situation d’un alpiniste perdu dans une tempête de neige, qui cherche à atteindre le fond de la vallée mais ne voit pas à un mètre devant lui. D’où la technique de rétropropagation. Prenons les exemples un par un: à chaque exemple, on prend la direction donnée par la rétropropagation de gradient, et on fait un petit pas dans cette direction : cela correspond pour l’alpiniste à faire un petit pas dans le sens de la descente. Et petit à petit, en descendant progressivement la pente comme une boule qui roule entraînée par la gravité, on espère trouver le fond de la vallée la plus profonde. Est-ce qu’on ne risque pas d’être bloqué dans une cuvette (un minimum local), ou arrêté en équilibre sur une crête ? Étonnamment, cela fonctionne : la plupart du temps, cette méthode permet de descendre longtemps, et de trouver très bon minimum. Cet algorithme a été amélioré depuis - par exemple, on ajoute à la boule une inertie pour l’empêcher de s’arrêter à la première cuvette - mais il reste très semblable.
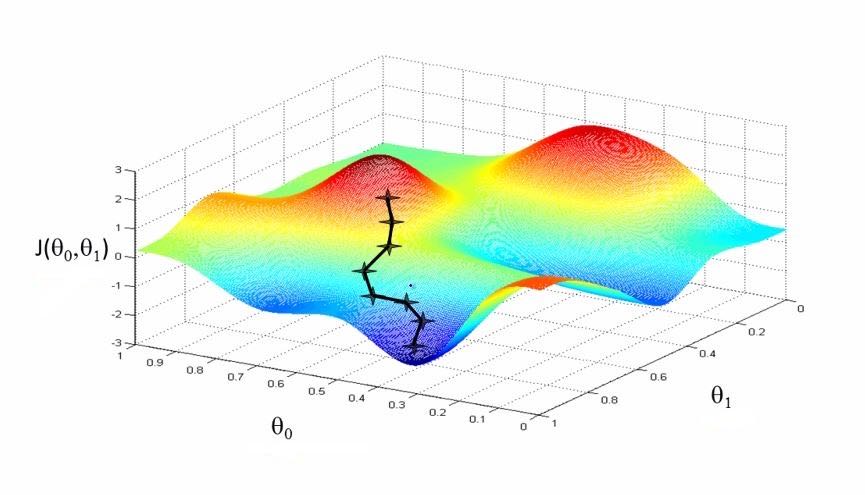
Cependant, pour LeCun et Hinton, qui avaient commencé une collaboration l’hiver n’était toujours pas terminé. Un nouvel algorithme, le SVM, similaire à un réseau à une seule couche, fonctionne très bien sur de petits jeux de données, et n’a pas besoin d’une procédure d’entraînement complexe. La procédure d’entraînement des réseaux de neurones “profonds” de LeCun, est plus complexe et sans garantie théorique de fonctionnement10, elle est donc jugée moins élégante. Les réseaux de neurones profonds sont donc encore une fois mis au ban de la communauté de l’intelligence artificielle.
Le “deep learning” se fait un nom
Ce qui va réellement changer la donne, c’est l’arrivée de jeux de données massifs, et le développement des GPU, des processeurs spécialisés en multiplication de matrices qui permettent aux réseaux de neurones de s’entraîner sur assez de données pour révéler leur puissance. Yann Lecun travaille désormais avec Geoff Hinton et Yoshua Bengio au Canadian Institute for Advanced Research (CIFAR) : ce trio de la “conspiration des neurones” ne désarme pas, et convainc une frange grandissante de chercheurs. Chaque année, de grand congrès sur l’apprentissage machine réunissent des chercheurs du monde entier : c’est là une occasion précieuse de faire connaître leurs idées et leurs résultats. En 2007, le congrès NeurIPS refuse sans explications l’atelier proposé par le trio. Qu’à cela ne tienne: ils organisent sur les fonds du CIFAR un atelier pirate, en affrétant leur propre bus pour acheminer les participants. Et c’est un succès: leur atelier accueille 300 chercheurs, c’est le plus couru du congrès! Cet événement marque l’adoption du terme “deep learning”, créé un an plus tôt par Hinton, dans la presse11 spécialisée. Le Deep learning s’impose alors progressivement, en particulier en traitement d’images. A partir de 2009, la communauté de chercheurs en vision essaye de réduire ses erreurs sur un immense banc de test appelé ImageNet: 12M d’images à classifier selon 22k catégories, créé par Fei-Fei Li, directrice du labo SAIL de Stanford. 2012 à la conférence ECCV, Alex Krizhevsky, étudiant de Hinton, dévoile son réseau appelé AlexNet. Devant une salle pleine à craquer, il annonce qu’il a battu le meilleur modèle au monde, en commettant deux fois moins d’erreur ! Progressivement, des réseaux de neurones s’imposent aux premières places sur tous les benchmarks. Richard Sutton a décrit cela comme une “amère leçon” (“bitter lesson”): toutes les approches les plus sophistiquées pour essayer de reproduire la manière dont nous croyons raisonner sont battues de loin par de simples empilements de neurones, pourvu qu’on ait entraîné ces derniers avec suffisamment de données et de puissance de calcul. Mais continuons de suivre Yann LeCun : porté par les succès du deep learning, il est engagé par Mark Zuckerberg pour lancer l’activité de recherche en IA chez Meta (alors Facebook). C’est lui qui a poussé depuis le grand effort de Meta pour proposer des modèles open-weights, c’est à dire proposant leurs poids et architectures publiquement.
Généralisation et Rasoir d’Ockham
Mais prenons un pas de recul. Nous avons plus haut comment ont été construites deux caractéristiques essentielles des réseaux de neurones: les réseaux de neurones sont des approximateurs universels, c’est à dire des systèmes pouvant reconstruire n’importe quelle fonction à partir de leurs entrées, et ils peuvent apprendre grâce à la rétro-propagation de LeCun et Hinton. Mais un tel système ne sera pas forcément utile. Par exemple, un dictionnaire a des entrés - les termes définis - et des sorties - les définitions. On peut associer aux termes du dictionnaire les définitions que l’on veut : c’est donc un approximateur universel. Il permet aussi un apprentissage : on peut éditer les définitions, comme le font chaque année le Larousse et le Petit Robert. Mais pourtant, dès qu’on veut chercher la définition d’un terme qui n’y figure pas, le dictionnaire n’est plus d’aucune utilité. Or pour les problèmes réels, on veut pouvoir donner au modèle une entrée qu’il n’ait jamais vue en entraînement et en obtenir tout de même une prédiction correcte. Par exemple, sur notre classificateur qui détermine l’animal présent sur une photo, on veut qu’une photo de chien donne toujours la prédiction “chien”, même si le chien en question appartient à une race qui n’a jamais été vue par le classificateur pendant son entraînement. En d’autres termes, on veut que notre modèle généralise les informations de ses données d’entraînement, par des proto-raisonnements comme “s’il y a un museau triangulaire plutôt qu’une trompe, c’est probablement un chien”. Un risque d’un approximateur universel naïf est de s’adapter aux données sans vraiment généraliser. On parlera d’“overfitting”, “sur-ajustement”. Voyez sur la figure ci-dessous une illustration de ce phénomène: le modèle apprend une limite bien trop complexe entre ses classes, et en conséquence se révèle inutile dès qu’on s’éloigne des exemples de son entraînement.
![Plusieurs modèles essayent de prédire en focntion de coordonnées [Latitude, Longitude] la sortie 'Est situé en France'. Ils prédisent 1 pour un 'Oui', 0 pour un 'Non'.](/assets/images/2024-08-15-brief-history-of-ai/france_graph_fr.png)
On veut apprendre de la bonne manière, en généralisant. C’est un problème difficile. Le meilleur moyen qu’on ait trouvé est de chercher la simplicité, en suivant ainsi le Rasoir d’Ockham. Ce principe méthodologique a été formulé ainsi par le moine franciscain anglais Guillaume d’Ockham: « Les multiples ne doivent pas être utilisés sans nécessité »12. Pour expliquer un phénomène, mieux vaut simplifier les choses en considérant d’abord l’explication qui fait intervenir le moins de facteurs, car c’est celle qui a l’hypothèse la moins forte. Nous utilisons souvent inconsciemment ce principe: ainsi même si un élève arrivant en retard au cours de maths de 8h30 peut expliquer son retard par un concours de circonstances complexe, le professeur va peut être se dire que l’élève a tout simplement tardé à se réveiller. C’est d’ailleurs cette recherche de simplicité qui invalide d’office la plupart des théories du complot : si le réchauffement climatique était un complot, il devrait nécessiter une coordination incroyable entre des milliers d’acteurs à travers la planète: météorologues, agriculteurs, biologistes… Il est beaucoup plus simple d’envisager que le climat se réchauffe effectivement, même si admettre cette thèse implique des conséquences désagréables. Ce principe est si puissant qu’il a été qualifié par le philosophe Bertrand Russel de “la maxime méthodologique suprême lorsqu’on philosophe”13. Plusieurs principes du deep learning peuvent être directement justifiés par le rasoir d’Ockham: entre autres la régularisation. Celle-ci consiste à ajouter dans l’entraînement du modèle une tendance pour tous les poids à se rapprocher de 0. Ainsi, un poids qui n’est pas incité par la rétropropagation à grandir pour favoriser une certaine sortie plutôt qu’une autre - et s’il n’est pas affecté par la rétropropagation, c’est qu’il est inutile - va naturellement tendre vers 0. Cela simplifie les frontières de décision (decision boundaries) du modèle, et aide empiriquement beaucoup la généralisation. Récapitulons : on veut donc que notre modèle soit capable d’approximer finement les données d’entraînement, tout en gardant des frontières de décision assez simples pour généraliser. C’est un équilibre délicat à trouver, et une grande partie de l’art du machine learning, l’apprentissage machine.
Meta-intelligence: concevoir des structures qui apprennent.
Rappelez vous la “bitter lesson” de Richard Sutton, qui disait que l’effort que l’on mettait à construire des structures de raisonnement sophistiquées était de peu d’utilité, comparée à la puissance de calcul brute lancée sur des millions d’exemples: maintenant relisez le paragraphe ci-dessus sur la régularisation, qui montre que donner à la machine les bons mécanismes peut aider son apprentissage. Est-ce que ce n’est pas une contradiction ? En fait, ces deux extraits ne se contredisent pas car ils portent sur deux niveaux différents de l’apprentissage. L’expression de Sutton porte sur le niveau de base, celui du raisonnement : dicter soi-même à la machine les raisonnements est inefficace. Mais si on remonte d’un niveau conceptuel, on peut donner au modèle les bonnes structures pour apprendre efficacement par lui-même lors de l’entraînement. En d’autres termes, on n’explique pas en détail la méthode pour résoudre chaque problème, mais on donne à la machine les conditions nécessaires pour trouver cette méthode lors de son apprentissage. C’est là tout l’art de l’intelligence artificielle d’aujourd’hui, et c’est ce qui me plaît énormément dans ce travail : il y a un côté démiurge à préparer toutes les conditions nécessaires de l’apprentissage, puis lancer cet apprentissage et voir l’optimisation se faire.
Attention
La classification d’image devient progressivement un problème résolu: les réseaux de neurones à convolution ont raison des benchmark les plus difficiles, et ils peuvent déjà aider les radiologues dans la détection de tumeurs cancéreuses. Mais le traitement de textes reste encore hors d’atteinte. En 2013, l’algorithme Word2vec permet de créer des représentations des mots comme des vecteurs, et avec une représentation des mots comme vecteurs, on peut commencer à traduire des textes14.
⚙️ Brique technique: Représenter les mots comme des vecteurs
D’abord, qu’est ce qu’un vecteur? C’est simplement une liste de nombres dans un ordre précis. Par exemple, des coordonnées dans l’espace en X, Y, Z forment un vecteur, en trois dimensions qu’on peut noter [X, Y, Z]. Inversement, tout vecteur peut être vu comme les coordonnées d’un point dans un espace. En une, en deux, ou en trois dimensions, nous pouvons nous les représenter : mais les vecteurs n’ont pas de limite de taille, ils peuvent être à mille dimensions. On peut faire des opérations sur les vecteurs : par exemple, pour deux vecteurs de taille égale, on peut multiplier chaque nombre de l’un par le nombre de l’autre à la même position (= pour la même dimension), puis sommer tous les produits pour obtenir un seul nombre. Cette opération s’appelle le produit scalaire. On peut aussi, bien sûr, les additionner ou les soustraire, en réalisant l’addition ou la soustraction sur chacune des dimensions une par une. Une idée qui a émergé assez tôt a été de représenter les mots comme des vecteurs : les dimensions pourraient représenter des concepts, par exemple l’axe féminin - masculin, grand-petit, pluvieux-ensoleillé, fort-faible… Cette approche a été implémentée par l’algorithme Word2vec en 201315, qui crée une représentation vectorielle pour plus d’un milliard de mots anglais. Cette représentation est extrêmement intéressante : les vecteurs obtenus ont entre eux des relations mathématiques qui reproduisent des liens conceptuels entre les mots qu’ils représentent. Par exemple, si on prend le vecteur qui représente le mot “reine”, qu’on lui soustrait le vecteur de “femme”, et qu’on ajoute “homme”, on obtient le vecteur de “roi” ! Ainsi, on s’aperçoit que les vecteurs des mots représentent des concepts comme la royauté ou la féminité.
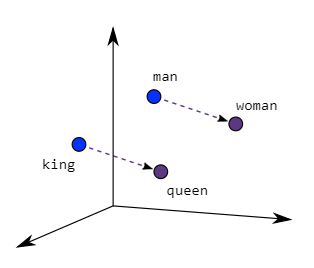
Pour ce faire, on peut placer côte à côte les différents vecteurs qui représentent les mots d’une phrase, et donner l’ensemble en entrée à un grand réseau de neurones, pour lui demander de prédire le mot à compléter. Cependant, jusqu’en 2017, les réseaux de neurones profonds ne sont pas vraiment capable de prendre en compte des interactions dynamiques entre leurs différentes entrées. Pour illustrer cette difficulté, prenons l’exemple de la traduction allemand => français. En allemand, le verbe est rejeté à la fin des propositions relatives, même si le sujet reste au début16.
“Ich frohe mich, dass er am Donnerstag Abend zum Essen kommt.” “Je réjouis moi, que il Jeudi soir pour dîner vient».
Mais ce n’est pas le cas pour une proposition non relative:
“Er kommt am Donnerstag Abend zum Essen, ich frohe mich” “Il vient Jeudi Soir pour dîner, je réjouis moi.”
Alors selon le contenu de la phrase, selon que la phrase soit formulée ou non comme une proposition relative, la position des entrées est complètement modifiée. Il faudrait donc pouvoir modéliser des interactions dynamiques selon les entrées, comme “si nous sommes dans une proposition relative, le sujet de la relative doit interagir fortement avec le tout dernier mot (le verbe) ». Or notre réseau de neurones n’en est pas capable, car il traite ses entrées uniquement en fonction de leur position : quelle que soit la phrase d’entrée, le premier mot sera toujours pris en compte de la même manière dans le réseau : en arrivant dans le neuron n°1 de la première couche, il sera ensuite renvoyé à tous les neurons de la couche 2 en fonction des poids pré-établis du réseau, et ainsi de suite pour toutes les couches.
La clé de ce problème est trouvée en 2017 dans un nouveau composant : l’auto-attention (self-attention) : l’article Attention is All You Need, qui a été cité depuis dans plus de cent mille autres articles, propose une nouvelle architecture de modèle nommée Transformers, qui bat les meilleurs modèles de son temps, tout en étant 100 fois moins coûteux à entraîner. La principale innovation est l’adoption d’un composant déjà existant, l’attention, appliquée d’une manière astucieuse : on calcule l ’attention de la phrase d’entrée envers elle même : cela permet de transformer la représentation de chaque mot pour incorporer un peu de la représentation des mots qui lui sont liés. Dans notre phrase en allemand ci dessus, “dass” (que) prendra un peu de la représentation de “er” (il) et un peu de celle de “kommt” (vient), même si ces mots sont situés aux extrémités de la phrase. Les couches d’auto-attention insérées dans le réseau à intervalles réguliers. Car souvenez vous qu’en remontant dans les couches du réseau, on crée des concepts de plus en plus abstraits : l’ajout de couches d’attentions à des zones hautes signifie qu’en plus de pouvoir faire interagir des mots lointains aux couches inférieures (“il faut accorder le verbe avec son sujet”), l’attention permet de faire interagir des concepts lointains aux couches supérieures (“la deuxième idée de cette phrase est en lien avec le titre du paragraphe”). Ainsi, on enrichit le modèle avec des interactions supplémentaires à tous les niveaux d’abstraction.
Un décodeur basé sur l’architecture Transformers
Voyons comment on utilise une architecture Transformers pour générer du texte. On part d’une phrase initiale, qui est en général le prompt donné par l’utilisateur.
Les mots de la phrase sont transformés en vecteurs. Enfin, pas exactement les mots. On préfère couper la phrase en “tokens”17, qu|i| s|ont| une| subdivision| des| m|ots| en| plus| pet|ites| unit|és.
Découper en tokens permet de réduire le vocabulaire nécessaire (car comme ils sont courts, l’ensemble des tokens est moins nombreux que celui de tous les mots), et permet aussi d’utiliser des similitudes entre mots. Par exemple, le suffixe “tion” indique en français une action ou le résultat de cette action : considérer “tion” comme une unité propre permettra au LLM de reconnaître le concept associé, quel que soit le mot à “tion” en présence, même s’il s’agit d’un néologisme inconnu du modèle tel que “tokenisation”.
Chaque token est donc transformé en un vecteur. Puis ces vecteurs passent dans l’architecture transformers, qui est un empilement de blocs transformers, chacun étant composé d’une couche de self-attention, puis une couche classique nommée “Feed-forward”. La dernière couche du réseau contient N neurons, avec N la taille du vocabulaire (ce sont bien des subword tokens, pas des mots complets) . On note i le numéro du neuron qui a la plus forte valeur de sortie : c’est donc le i-ème token du vocabulaire qui est choisi.
Ce token est donc ajouté à la suite des autres tokens. Et ainsi on obtient une nouvelle phrase, qui correspond à la phrase initial, augmentée d’un nouveau token. On relance ensuite tout le processus en utilisant cette phrase augmentée en entrée, pour ajouter encore un nouveau token. Et ainsi, pas à pas, on agrandit la phrase, jusqu’à ce que le token généré soit un token spécifique,
Méthodes d’apprentissage
On classifie plusieurs méthodes d’apprentissage en fonction des données utilisée.
Apprentissage supervisé : c’est celui utilisé dans notre exemple du classifieur d’images. Cela veut dire qu’on a créé un jeu de données où chaque exemple a été annoté. Par exemple, “l’image 1 est un chien”, “l’image 2 est un chat”. Ce sont souvent des jeux de donnée riches en information pour le modèle, mais très coûteux à produire quand il faut des millions d’exemples !
Apprentissage non supervisé : une solution plus économique est de pouvoir entraîner son modèle sur des données non annotées. Mais la plupart des modèles ne peuvent pas s’entraîner ainsi: car comment trouver si la prédiction est correcte ou non, quand on n’a pas de référence ? Si les modèles peuvent s’entraîner selon cette méthode, c’est une chance. Les méthodes de “clustering”, qui prennent un ensemble de vecteurs et les regroupent en “cluster”, peuvent fonctionner de manière non supervisée. Et heureusement, les architectures decoder le peuvent aussi! Voir l’exemple donné ci dessus.
Apprentissage par renforcement (Reinforcement learning ) : quand on n’a même pas de jeu de données, on peut utiliser le reinforcement learning. Cette méthode est très utilisée en robotique, où la dimension des sorties possibles est immense : au contraire de l’exemple de classification d’images où la prédiction est choisie parmi une une dizaine de classes, pour un bras robotique à cinq degrés de libertés qui fait un mouvement pendant dix secondes, le champ des trajectoires possibles est immenses, ce qui rend un jeu de données pré-construit beaucoup moins utile. C’est un champ entièrement à part, qui fait appel à des optimisations complexes.
Alors pour l’instant, on a gardé le Décodeur qui génère sa réponse token par token, quitte à inventer des réponses fantaisistes s’il n’a rien de cohérent à compléter. Ce dernier cas est appelé hallucinations : le modèle donne une réponse probable mais complètement inventée.
Par exemple, à la question “Combien pèse un oeuf de vache ? », certains modèles complèteront aussitôt quelque chose comme : “Combien pèse un oeuf de vache ? Un oeuf de vache pèse de 2 à 5 kilogrammes, selon la race de la vache.
Passage à l’échelle : les Large Language Models
En octobre 201818, nouveau coup de tonnerre dans le monde de la recherche : des chercheurs de Google (encore une fois) publient BERT, une architecture basée sur transformers, qui bat les meilleurs modèles sur 11 tâches différentes. En général, battre un benchmark est déjà digne d’une publication : en battre 11 est un exploit retentissant ! Comment l’ont-ils réalisé ? Ils ont utilisé l’architecture Transformers avec très peu de modification, seulement avec un entraînement bien fait, et jusqu’à 24 couches empilées au lieu de 6, ce qui fait monter le modèle à 340 millions de paramètres - c’est énorme pour l’époque. C’est la début d’une ruée vers l’or : tout le monde veut utiliser l’architecture de BERT. Facebook publie quelques mois plus tard RoBERTa, où ils narguent les chercheurs de Google en reprenant leur modèle avec une architecture strictement identique, mais en l’entraînant mieux pour obtenir une performance supérieure. Microsoft publiera sa propre version, DeBERTa, un an plus tard, avec une architecture modifiée. Puis, comme les résultats obtenus par les modèles s’améliorent toujours à mesure que leur nombre de paramètre augmentait, on se met à entraîner des modèles de plus en plus gros. On parle ainsi de Large Language Models (LLMs), les “grands modèles de langage”.
En fait, ce qui a époustouflé les chercheurs à ce moment là, c’est un principe qui avait déjà été mentionné par des chercheurs d’OpenAI en 201719, un an avant qu’ils publient leur premier GPT (pour “Generative Pre-trained Transformer”). Le projet consistait à faire de l’ ”analyse de sentiment”, c’est à dire interpréter si l’opinion générale exprimée par un court texte est positive ou négative. C’est une tâche sur laquelle les chercheurs ont passé des dizaines d’années à créer des jeux de données volumineux, en annotant à la main des milliers d’avis utilisateurs récoltés sur des sites commerciaux. Au contraire, le projet d’OpenAI en 2017 consistait à entraîner un modèle qui prédise simplement le texte d’un avis utilisateur, lettre par lettre (on n’était même pas encore au token). Une fois ce modèle entraîné à prédire le texte, les chercheurs ont réalisé qu’il était excellent en analyse de sentiment, malgré le fait qu’il n’ait jamais été entraîné pour cette tâche spécifique. C’est un exemple du phénomène de “transfert d’apprentissage” : l’apprentissage d’un modèle sur une tâche spécifique augmente également ses performances sur une autre tâche. L’explication donnée le plus souvent pour ce phénomène de transfert d’apprentissage est que l’entraînement à modéliser du texte donne au modèle une représentation statistique du langage assez puissante pour le rendre ensuite plus performant sur d’autres tâches. Il y a encore un débat très vif sur le fait que ces modèles comprennent vraiment le langage, ainsi que les phénomènes sociaux et physiques qu’il représente20 : certains défendent l’idée qu’au fil de leur apprentissage, les modèles développent un vrai modèle interne du monde. Probablement pas un modèle proche de celui que nous envisagerions - si tant est que nous en ayons un commun -, mais un modèle utile tout de même. Ainsi, nombre de propriétés dites “émergentes” ont été découvertes à mesure qu’on entraînait des modèles de plus en plus grands, de manière imprévisible. Par exemple, en pré-entraînant un modèle de plus en plus grand sur le même corpus de texte, on s’aperçoit qu’à partir d’une certaine taille, il passe progressivement de ~0 à ~100% de performance sur une tâche complètement annexe. Un exemple flagrant en est le rapport technique de GPT-421, qui montre des dizaines d’examens où le modèle est devenu bien meilleur, sans avoir été entraîné sur ces examens22. En fait, il a été montré que ce déblocage subit de capacités nouvelles est le résultat naturel d’une augmentation progressive (ou incrémentale) de performance des LLM23. Pour prendre une analogie dans le monde réel : si je cours le marathon en 10h, je ne vais gagner aucun championnat. Et réduire progressivement mon temps, 10 minutes par 10 minutes, ne fera toujours pas frémir mon compteur de médailles… Jusqu’aux trois étapes entre 2h30 et 2h, où je passerai soudain d’une performance départementale à celle de champion du monde. Evidemment, pour nous humains ce sont ces dernières tranches de dix minutes qui sont les plus dures à obtenir - car nous partons tous avec le même matériel (notre corps), et l’effort pour le changer est immense. Mais pour une machine dont l’architecture peut être modifiée à volonté, ce seuil des 2h n’est pas plus difficile à passer que les précédents. Résultat notable : l’émergence de chacune de ces capacités à partir d’une certaine taille de modèle est imprévisible. Depuis 2017, quelques innovations importantes ont encore amélioré les Large Language Models: données d’entraînement massives et de meilleure qualité, grouped-query attention24, position encodée par des matrices de rotation25, activation SwiGLU26… Mais la base reste la même: une architecture Transformers. Seulement, on ajoute aux réseaux de plus en plus de couches de neurons, de neurones par couche et de têtes d’attention. Les LLM pré-entraînés sur des texte de plus en plus immenses ont peu à peu pris les premières places sur tous les tests possibles, dans toutes les tâches et toutes les modalités. A croire qu’on aurait trouvé une recette universelle pour l’intelligence.
-
Permise par l’architecture pensée par von Neumann en 1945 et implémentée pour l’EDVAC en 1952, qui séparait pour la première fois le logiciel (software) de son support mécanique (hardware), permettant ainsi de coder dans se soucier de mécanique. ↩
-
Le mécanisme décrit ici est celui de la fonction ReLU, mais bien d’autres ont été construits. Aujourd’hui, c’est SwiGLU qui est utilisé dans les modèles Llama-3 de Meta. Mais cela changera probablement un jour! ↩
-
Le New York Times écrivait en 1958 que c’était l’“l’embryon d’un ordinateur électronique dont la Marine espère qu’il marche, parle, voie, écrive, se reproduise lui-même et soit conscient de son existence” ↩
-
A ce propos, voir la critique d’Hubert Dreyfus, basé sur le Ready-to-hand et le present-to-hand d’Heidegger. ↩
-
Y. LeCun, Quand la Machine apprend. ↩
-
H. J. Kelley, “Gradient Theory of Optimal Flight Paths”, ARS Journal, vol. 30, nᵒ 10, p. 947‑954, oct. 1960, doi: 10.2514/8.5282. ↩
-
Pour ceux qui veulent se former techniquement, je vous recommande d’aller lire le papier écrit par LeCun sur le sujet, https://yann.lecun.com/exdb/publis/pdf/lecun-88.pdf. Il redémontre de manière limpide toutes les équations qui conduisent à la rétropropagation (backpropagation). ↩
-
Il s’agit de la base MNIST: “MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges” [En ligne]. Disponible sur: https://yann.lecun.com/exdb/mnist/ ↩
-
En anglais, “loss function”, souvent abrégée en “loss”. ↩
-
Si l’on représente l’erreur moyenne commise par le réseau en fonction de ses paramètres, on obtient une fonction non convexe. L’entraînement consiste à trouver le minimum global de cette fonction, mais en raison de cette non-convexité, il n’est pas garanti que la backpropagation permette de le trouver ↩
-
Y. LeCun, Quand La Machine apprend. ↩
-
En latin: Pluralitas non est ponenda sine necessitate ↩
-
B. Russel, On the Nature of Acquaintance, p. 1456 ↩
-
Les premiers réseaux performants pour la traduction de texte ont été les Recurrent Neural Networks (RNN) ↩
-
T. Mikolov, K. Chen, G. Corrado, et J. Dean, “Efficient Estimation of Word Representations in Vector Space”, 6 septembre 2013, arXiv: arXiv:1301.3781. doi: 10.48550/arXiv.1301.3781. ↩
-
C’est peut être la raison pour laquelle les débats politiques allemands se coupent moins la parole et semblent plus respecteux : car on a du mal à savoir ce que dit son adversaire avant qu’il ait terminé sa phrase ! ↩
-
Ce processus porte le doux nom de “subword tokenization” ↩
-
Date de publication sur le site Arxiv, où les papiers peuvent être publiés très rapidement sans passer par les longs processus de validation des journaux ou conférences. Au moment d’être publié à la conférence ICLR en mai 2019, leur papier cumule déjà 600 citations ! ↩
-
A. Radford, R. Jozefowicz, et I. Sutskever, “Learning to Generate Reviews and Discovering Sentiment”, 6 avril 2017, arXiv: arXiv:1704.01444. doi: 10.48550/arXiv.1704.01444. ↩
-
M. Mitchell et D. C. Krakauer, “The Debate Over Understanding in AI’s Large Language Models”, 10 février 2023. doi: 10.1073/pnas.2215907120. ↩
-
OpenAI et al., “GPT-4 Technical Report”, 4 mars 2024, arXiv: arXiv:2303.08774. doi: 10.48550/arXiv.2303.08774. ↩
-
Attention toutefois : à ces échelles, il faut pour entraîner les modèles leur donnée des données d’entraînement massives, récupérées sans trop de discrimination sur tout Internet. Il arrive alors fréquemment que les réponses à certains tests aient déjà été vues par le modèles au cours de son entraînement, et mémorisées, ce qui fausse le test. On parle de “contamination” du jeu de données de test. ↩
-
R. Schaeffer, B. Miranda, et S. Koyejo, “Are Emergent Abilities of Large Language Models a Mirage?”, 22 mai 2023, arXiv: arXiv:2304.15004. doi: 10.48550/arXiv.2304.15004. ↩
-
J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebrón, et S. Sanghai, “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”, 23 décembre 2023, arXiv: arXiv:2305.13245. doi: 10.48550/arXiv.2305.13245. ↩
-
J. Su, Y. Lu, S. Pan, A. Murtadha, B. Wen, et Y. Liu, “RoFormer: Enhanced Transformer with Rotary Position Embedding”, 8 novembre 2023, arXiv: arXiv:2104.09864. doi: 10.48550/arXiv.2104.09864. ↩
-
N. Shazeer, “GLU Variants Improve Transformer”, 12 février 2020, arXiv: arXiv:2002.05202. doi: 10.48550/arXiv.2002.05202. ↩